Python数据挖掘框架sklearn教程—KMeans聚类
聚类是一种重要的无监督学习算法,在许多领域受到广泛应用,包括机器学习,数据挖掘,模式识别,图像分析以及生物信息。聚类是把相似的对象通过静态分类的方法分成不同的组别或者更多的子集(subset),这样让在同一个子集中的成员对象都有相似的一些属性,常见的包括在坐标系中更加短的空间距离等。聚类算法有很多巧妙地用途,例如可以用聚类来发现噪音数据、用聚类来分离图像的前景和背景。
本文介绍如何sklearn的K-Means来聚类iris数据集,代码如下:
#coding=utf-8
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
iris = datasets.load_iris()
original_x = iris.data
#读取内置的iris数据集
#原始iris数据集有4个维度,为了方便展示到2D图
#我们用第一列加上第三列、第二列加上第四列获得2个新特征
#用这2个新特征取代原来的4个特征
datas = original_x[:, :2] + original_x[:, 2:]
#计算最大值最小值,用于绘图时计算坐标范围
border = 0.5
x_min, x_max = datas[:, 0].min() - border, datas[:, 0].max() + border
y_min, y_max = datas[:, 1].min() - border, datas[:, 1].max() + border
#进行KMeans聚类
kmeans = KMeans(init='k-means++', n_clusters = 3)
kmeans.fit(datas)
#计算每一类到其中心距离的平均值,作为绘图时绘制圆圈的依据
distances_for_labels = []
for label in range(kmeans.n_clusters):
distances_for_labels.append([])
for i, data in enumerate(datas):
label = kmeans.labels_[i]
center = kmeans.cluster_centers_[label]
distance = np.sqrt(np.sum(np.power(data - center, 2)))
distances_for_labels[label].append(distance)
ave_distances = [np.average(distances_for_label) for distances_for_label in distances_for_labels]
#绘图
fig, ax = plt.subplots()
ax.set_aspect('equal')
#设置坐标范围
ax.set_xlim((x_min, x_max))
ax.set_ylim((y_min, y_max))
#绘制每个Cluster
for label, center in enumerate(kmeans.cluster_centers_):
radius = ave_distances[label] * 1.5
ax.add_artist(plt.Circle(center, radius = radius, color = "r", fill = False))
#根据每个数据的真实label来选择数据点的颜色
plt.scatter(datas[:, 0], datas[:, 1], c = iris.target)
plt.show()
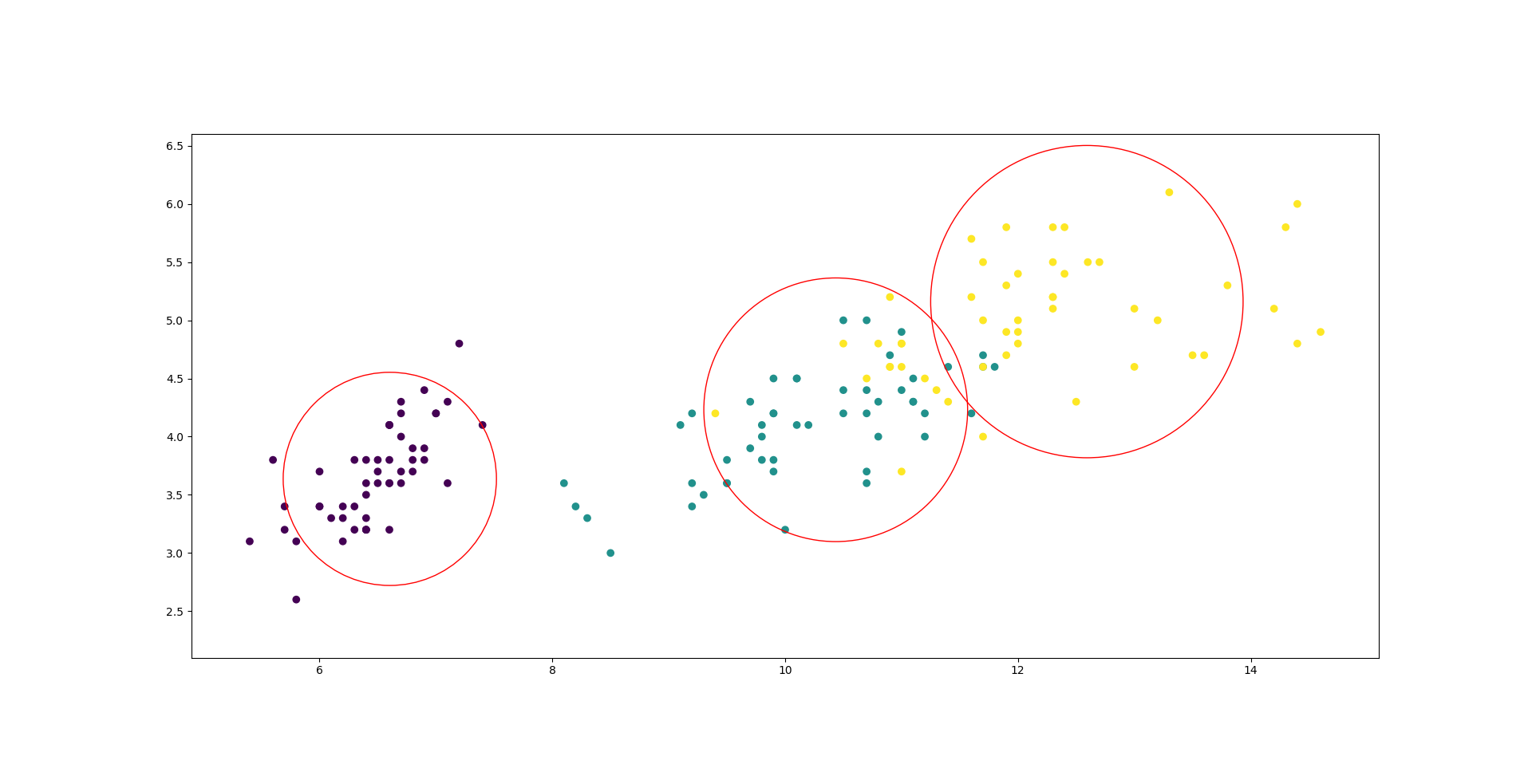
运行结果:
欢迎加QQ群532836339讨论机器学习: