k-means算法如何自动选择k值(类别数量)
k-means算法中k值的确定是一个非常重要的问题,当数据维度较少、且每类数据较为分散时,可以通过数据可视化的方法来人工确定k值。
但当数据维数较高、数据分布较为混乱时,数据可视化已无法帮助我们通过人工的方法来确定k值。且很多场景下对算法的自动化程度有较高的要求,人工确定k值并不现实,因此k值的自动确定是一个非常重要的研究问题。
k-means中k值的确定有很多种方法:
1.Elbow方法
Elbow方法主要基于一个对聚类效果的度量指标——the percentage of variance explained,该指标是the sum of squares between groups与the sum of squares total的商。
the sum of squares between groups的公式如下:
![]()
其中,i是每个类别的标号,ni表示每个类别中数据点的数量,Mi是每个类别的中心点,GM是所有数据点的中心点。
the sum of squares total的公式如下:
SST = Σ(X – GM)²
其中X表示每个数据点,GM是所有数据点的中心点。
分别将k设置为2、3、4…,执行k-means至收敛,分别计算最终的the percentage of variance explained,如下图所示:
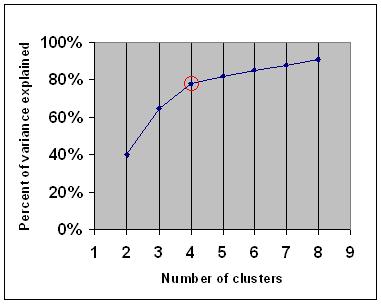
从图中可以看出,当k从4变化为5时the percentage of variance explained获得的增益开始明显下降,因此示例中,合适的k值为4。
未完待续